According to Oracle Doc, Oracle does not index table rows in which all key columns are null except in the case of bitmap indexes (Database SQL Language Reference).
Therefore, in a composite B-tree index, if there exists one column which contains a non-null value, the row will be indexed. Since local prefixed indexes is a composite index which includes partition keys on the leading edge of the index definition, and partition keys are never all null, all rows are always indexed.
For applications, it means that local prefixed indexes is always usable, but not local nonprefixed indexes. In the performance point of view, Column Null Values is a torque on Local prefixed vs. nonprefixed indexes (Number_of_Null_Columns x Number_of_Rows).
Taking the same example from Expert Oracle Database Architecture Page 593, but updating Column b of one row in PART_1 as NULL.
create table partitioned_table
( a int,
b int,
data char(20)
)
partition by range (a)
(
partition part_1 values less than(2) tablespace p1,
partition part_2 values less than(3) tablespace p2
)
/
create index local_prefixed on partitioned_table (a,b) local;
create index local_nonprefixed on partitioned_table (b) local;
insert into partitioned_table
select mod(rownum-1,2)+1, rownum, 'x' from all_objects where rownum <= 1000;
update partitioned_table set b=null where a=1 and b=99;
begin
dbms_stats.gather_table_stats
( user,
'PARTITIONED_TABLE',
cascade=>TRUE );
end;
/
we can see PART_1 having one row with Column b being NULL:
select a, count(*), count(a), count(b)
from partitioned_table group by a;
A COUNT(*) COUNT(A) COUNT(B)
---------- ---------- ---------- ----------
1 500 500 499
2 500 500 500
select index_name, partition_name, num_rows
from dba_ind_partitions
where index_name in ('LOCAL_PREFIXED', 'LOCAL_NONPREFIXED');
INDEX_NAME PARTITION_NAME NUM_ROWS
------------------------------ ------------------------------ ----------
LOCAL_NONPREFIXED PART_1 499
LOCAL_NONPREFIXED PART_2 500
LOCAL_PREFIXED PART_1 500
LOCAL_PREFIXED PART_2 500
Now if we run following queries, all of them will use LOCAL_PREFIXED index.
select /*+ index(t local_prefixed) */ count(a) from partitioned_table t where a = 1 and b is null;
select /*+ index(t local_nonprefixed) */ count(a) from partitioned_table t where a = 1 and b is null;
select /*+ index(t local_prefixed) */ count(a) from partitioned_table t where b is null;
select /*+ index(t local_nonprefixed) */ count(a) from partitioned_table t where b is null;
select /*+ index(t local_prefixed) */ count(a) from partitioned_table t where a is null and b is null;
select /*+ index(t local_nonprefixed) */ count(a)
from partitioned_table t where a is null and b is null;
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Pstart| Pstop |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 1 (0)| | |
| 1 | SORT AGGREGATE | | 1 | 7 | | | |
| 2 | PARTITION RANGE SINGLE| | 1 | 7 | 1 (0)| 1 | 1 |
|* 3 | INDEX RANGE SCAN | LOCAL_PREFIXED | 1 | 7 | 1 (0)| 1 | 1 |
-----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("A"=1 AND "B" IS NULL)
For the queries with partition key being NULL, PARTITION RANGE EMPTY elimination is used.
Even though PART_2 does not contain any rows whose Column b being NULL, LOCAL_NONPREFIXED index can neither be used in the following queries.
select /*+ index(t local_prefixed) */ count(a) from partitioned_table t where a = 2 and b is null;
select /*+ index(t local_nonprefixed) */ count(a) from partitioned_table t where a = 2 and b is null;
select /*+ index(t local_nonprefixed) */ count(a)
from partitioned_table partition (part_2) t where b is null;
Monday, December 22, 2014
Monday, November 10, 2014
reverse key index: the remedy is worse than the symptoms
In general, reverse key index mitigates data block contention (buffer busy waits) when inserting monotonically increasing key into right-most index by multiple concurrent sessions. The disadvantage is its inability to support range scan.
Based on AWR report, this Blog will try to list the main checking points when using reverse key index, and shows how to find the acceptable trade-off between benefits and drawbacks. The whole discussion stems from author's experience in single instance DB (non-RAC).
1.Top 5 Timed Foreground Events
When some events like:
enq: TX - index contention
buffer busy waits
read by other session
appear in Top Events, reverse key index is hastily resorted.
However "db file sequential read" should be checked after experimenting reverse key index since all the original inserts of right-most single index block are now spread over many blocks. One should try to balance the fast logical buffer activity against slow physical disk access.
2. Time Model Statistics
Since more blocks are involved with reverse key index, DBWR is more active, and therefore:
background elapsed time
background cpu time
are augmented.
Higher "db file parallel write" and "DBWR checkpoint buffers written" can also be observed,
3. SQL ordered by Gets
The insert statement generates a lower "Buffer Gets" in case of reverse key index.
4. SQL ordered by Reads
Reverse key index incurs a higher "Physical Reads" for the insert statement, almost 1 "Reads per Exec" since each insert touches a single different block.
Moreover, the queries using the index also cause higher "Physical Reads" due to the wide spreading of conceptually adjacent indexes, but physically isolated.
5. Segment Statistics
The absolute figures of buffer contentions and physical activities can be extracted by looking:
Segments by Logical Reads
Segments by Row Lock Waits
Segments by Buffer Busy Waits
Segments by Physical Reads
Segments by Physical Writes
Based on them, a quick magnitude comparison of IO and Memory associated with system statistics can give an approximate assessment of reverse key index.
D-1. Expert Oracle Database Architecture said:
One way to improve the performance of the PL/SQL implementation with a regular index would be to introduce a small wait. That would reduce the contention on the right-hand side of the index and increase overall performance (Page 439)
reverse key index (designed for Oracle RAC) (Page 491)
Usually, sequence insert in OLTP system is inherently operated with a slight delay due to the interactive nature of OLTP, whereas Batch processing can be impeded by heavy buffer contention of index blocks.
D-2. Introduction To Reverse Key Indexes: Part III (A Space Oddity) and
Oracle B-Tree Index Internals:Rebuilding The Truth wrote:
If the "right-most" block is filled by the maximum current value in the index, Oracle performs 90-10 block splits meaning that full index blocks are left behind in the index structure.
I prefer to call them 99-1 block splits as 90-10 is misleading.
Generally reverse key index tends to use 50-50 Split, which costs more block creates and touches.
In principle, it shifts single block buffer contention to multiple accesses of separate blocks.
D-3. Oracle MOS has a cautious Doc:
Using Reverse Key Indexes For Oracle 11.2.0.2 (Doc ID 1352477.1)
However, it must be noted that : Now the entire index had better be in the buffer cache whereas before - only the hot right hand side needed to be in the cache for efficient inserts. If the index cannot fit into the cache we might well have turned a buffer busy wait into a physical IO wait which could be even worse (the remedy is worse than the symptoms).
The reminiscent last remark is voted as the title of this Blog.
D-4. Oracle MOS Doc:
Troubleshooting 'enq: TX - index contention' Waits in a RAC Environment. (Doc ID 873243.1)
explains "enq: TX - index contention":
The reason for this is the index block splits while inserting a new row into the index. The transactions will have to wait for TX lock in mode 4, until the session that is doing the block splits completes the operations.
and suggests to look Instance Activity Stats:
root node splits
branch node splits
leaf node splits
leaf node 90-10 splits
In a DB, reverse key index can be found by:
select * from dba_indexes where index_type = 'NORMAL/REV';
Based on AWR report, this Blog will try to list the main checking points when using reverse key index, and shows how to find the acceptable trade-off between benefits and drawbacks. The whole discussion stems from author's experience in single instance DB (non-RAC).
1.Top 5 Timed Foreground Events
When some events like:
enq: TX - index contention
buffer busy waits
read by other session
appear in Top Events, reverse key index is hastily resorted.
However "db file sequential read" should be checked after experimenting reverse key index since all the original inserts of right-most single index block are now spread over many blocks. One should try to balance the fast logical buffer activity against slow physical disk access.
2. Time Model Statistics
Since more blocks are involved with reverse key index, DBWR is more active, and therefore:
background elapsed time
background cpu time
are augmented.
Higher "db file parallel write" and "DBWR checkpoint buffers written" can also be observed,
3. SQL ordered by Gets
The insert statement generates a lower "Buffer Gets" in case of reverse key index.
4. SQL ordered by Reads
Reverse key index incurs a higher "Physical Reads" for the insert statement, almost 1 "Reads per Exec" since each insert touches a single different block.
Moreover, the queries using the index also cause higher "Physical Reads" due to the wide spreading of conceptually adjacent indexes, but physically isolated.
5. Segment Statistics
The absolute figures of buffer contentions and physical activities can be extracted by looking:
Segments by Logical Reads
Segments by Row Lock Waits
Segments by Buffer Busy Waits
Segments by Physical Reads
Segments by Physical Writes
Based on them, a quick magnitude comparison of IO and Memory associated with system statistics can give an approximate assessment of reverse key index.
Discussion
D-1. Expert Oracle Database Architecture said:
One way to improve the performance of the PL/SQL implementation with a regular index would be to introduce a small wait. That would reduce the contention on the right-hand side of the index and increase overall performance (Page 439)
reverse key index (designed for Oracle RAC) (Page 491)
Usually, sequence insert in OLTP system is inherently operated with a slight delay due to the interactive nature of OLTP, whereas Batch processing can be impeded by heavy buffer contention of index blocks.
D-2. Introduction To Reverse Key Indexes: Part III (A Space Oddity) and
Oracle B-Tree Index Internals:Rebuilding The Truth wrote:
If the "right-most" block is filled by the maximum current value in the index, Oracle performs 90-10 block splits meaning that full index blocks are left behind in the index structure.
I prefer to call them 99-1 block splits as 90-10 is misleading.
Generally reverse key index tends to use 50-50 Split, which costs more block creates and touches.
In principle, it shifts single block buffer contention to multiple accesses of separate blocks.
D-3. Oracle MOS has a cautious Doc:
Using Reverse Key Indexes For Oracle 11.2.0.2 (Doc ID 1352477.1)
However, it must be noted that : Now the entire index had better be in the buffer cache whereas before - only the hot right hand side needed to be in the cache for efficient inserts. If the index cannot fit into the cache we might well have turned a buffer busy wait into a physical IO wait which could be even worse (the remedy is worse than the symptoms).
The reminiscent last remark is voted as the title of this Blog.
D-4. Oracle MOS Doc:
Troubleshooting 'enq: TX - index contention' Waits in a RAC Environment. (Doc ID 873243.1)
explains "enq: TX - index contention":
The reason for this is the index block splits while inserting a new row into the index. The transactions will have to wait for TX lock in mode 4, until the session that is doing the block splits completes the operations.
and suggests to look Instance Activity Stats:
root node splits
branch node splits
leaf node splits
leaf node 90-10 splits
In a DB, reverse key index can be found by:
select * from dba_indexes where index_type = 'NORMAL/REV';
Thursday, November 6, 2014
Low High Water Mark, High High Water Mark, and Parallel Query
Recently we saw a 4 hours running parallel SELECT:
select /*+ parallel(t,2) parallel_index(t,2) dbms_stats cursor_sharing_exact
use_weak_name_resl dynamic_sampling(0) no_monitoring no_substrb_pad
*/count(*), count("ID"), count(distinct "ID"),
sum(sys_op_opnsize("ID")), substrb(dump(min("ID"),16,0,32),1,120),
substrb(dump(max("ID"),16,0,32),1,120),
...
from "X"."TABLE_1" sample ( 5.0000000000) t;
which is generated when executing:
dbms_stats.gather_table_stats('X', 'TABLE_1', estimate_percent=>5, degree=>2);
on both Oracle 11.2.0.3.0 and 11.2.0.4.0.
The table is about 160GB and contains 20m blocks (8K per block) in ASSM LMT Managed Tablespaces, all the columns are number or varchar2.
AWR report shows the SELECT statement statistics:
Buffer Gets 14,805,983,166
Physical Reads 40,474,817
UnOptimized Read Reqs 1,881,624
TABLE_1 Segment Statistics:
Segments by Logical Reads 16,312,997,632
Segments by Physical Reads 38,580,663
Segments by Direct Physical Reads 38,557,265
Segments by Table Scans 263,660
Segments by Buffer Busy Waits 53,492
At first, one surprising big "Table Scans" indicates certainly abnormal behavior.
Huge number of "Buffer Gets" and double "Physical Reads" also explain the slow running.
"Table Scans" for Parallel Query is the Execs of "TABLE ACCESS FULL" below "PX BLOCK ITERATOR" in xplan, since "PX BLOCK ITERATOR" at first breaks up the table into granules which are then dispatched to each PX slaves. In the case of SAMPLE select, it is the Execs of "TABLE ACCESS SAMPLE BY ROWID RANGE".
The number of granules processed by each PX slave is controlled by two hidden parameters:
_px_min_granules_per_slave: minimum number of rowid range granules to generate per slave default 13
_px_max_granules_per_slave: maximum number of rowid range granules to generate per slave default 100
For instance, parallel(t,2) contributes minimum 26 (2*13) "Table Scans", and maximum 200 (2*100);
and parallel(t,16) generates minimum 208 (16*13) "Table Scans", and maximum 1600 (16*100);
Therefore when increasing degree from 2 to 16,
dbms_stats.gather_table_stats(null, 'TABLE_1', estimate_percent=>5, degree=>16);
will take 32 (8*4) hours. That is a counterintuitive behavior when using parallel query.
The "Table Scans" can be monitored by:
select * from V$segment_statistics
where object_name = 'TABLE_1' and statistic_name = 'segment scans';
The hidden parameters can be changed by, for example:
alter system set "_px_min_granules_per_slave"=19;
Searching MOS, we found:
which says:
Scans using Parallel Query on ASSM tablespaces on 10.2 can be slower compared to 9.2 when there is a wide separation between the High and Low High Water Mark. There can be High contention and/or a large number of accesses to bitmap blocks in PQ slaves during extent-based scans
of table/index segments.
AWR reports may show "read by other session" as one of the top wait events and Section "Buffer Wait Statistics" may report "1st level bmb" as the most important wait class.
The difference between the High and Low High Water Mark can be identified by running procedure DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM with parameter check_only=1.
The AWR report confirms the above notice:
read by other session Waits=11,302,432
1st level bmb Waits=98,112
and calling:
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM('X','TABLE_1','TABLE',NULL,1) returns 1.
MOS also gives a Workaround:
Execute procedure DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM with check_only=0 to synchronize the gap between the High and Low High Water Mark.
IMPORTANT: A patch for bug 6493013 must be installed before running that procedure.
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM only signals the existence of the gap,
but does not report the size of the gap. However, the width between low HWM and the HWM
determines the performance of full table scan (see Section "Segment Space and the High Water Mark" later in this Blog).
To find the exact gap size, we can dump segment header by:
alter system dump datafile 94 block 2246443;
Here the output:
-----------------------------------------------------------------
Extent Header:: spare1: 0 spare2: 0 #extents: 1242809 #blocks: 19884944
last map 0x9d178f31 #maps: 2446 offset: 2720
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19804642
mapblk 0x9d178f31 offset: 441
Unlocked
--------------------------------------------------------
Low HighWater Mark :
Highwater:: 0x1e243af9 ext#: 448588 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 7177417
mapblk 0x1e242fd9 offset: 225
Level 1 BMB for High HWM block: 0x9d179910
Level 1 BMB for Low HWM block: 0x1aace0d9
--------------------------------------------------------
We can see there are 19,804,642 blocks below Highwater: 0x9d179f90, but only 7,177,417 below Low HighWater Mark: 0x1e243af9. So 12,627,225 (19804642-7177417) are between (64%).
The distance between Level 1 BMB High HWM block and Low HWM block is 2,188,032,055
(0x9d179910 - 0x1aace0d9 = 2635569424 - 447537369 = 2188032055).
After synchronizing by:
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM('X','TABLE_1','TABLE',NULL,0)
the gap is gotten closed as showed by anew header dump:
-----------------------------------------------------------------
Extent Header:: spare1: 0 spare2: 0 #extents: 1242809 #blocks: 19884944
last map 0x9d178f31 #maps: 2446 offset: 2720
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19804642
mapblk 0x9d178f31 offset: 441
Unlocked
--------------------------------------------------------
Low HighWater Mark :
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19884944
mapblk 0x9d178f31 offset: 441
Level 1 BMB for High HWM block: 0x9d179910
Level 1 BMB for Low HWM block: 0x9d179910
--------------------------------------------------------
In "Low HighWater Mark" section:
-. "#blocks below: 7177417" is updated to "#blocks below: 19884944" (even bigger than 19804642).
-. "Level 1 BMB for Low HWM block: 0x1aace0d9" is changed to "Level 1 BMB for Low HWM block: 0x9d179910",
which got the same block id (0x9d179910) as "Level 1 BMB for High HWM block: 0x9d179910".
by chance, we also notice that the gap between the High and Low High Water Mark can be synchronized by:
select /*+ parallel(t, 2) */ count(*) from TABLE_1 t;
Oracle has a detail description about High HWM (or simply HWM) and Low HWM
(see Segment Space and the High Water Mark):
Suppose that a transaction inserts rows into the segment. The database must allocate a group of blocks to hold the rows. The allocated blocks fall below the HWM. The database formats a bitmap block in this group to hold the metadata, but does not preformat the remaining blocks in the group.
The low HWM is important in a full table scan. Because blocks below the HWM are formatted only when used, some blocks could be unformatted, as in Figure 12-25. For this reason, the database reads the bitmap block to obtain the location of the low HWM. The database reads all blocks up to the low HWM because they are known to be formatted, and then carefully reads only the formatted blocks between the low HWM and the HWM.
We can see that ASSM uses bitmap to track the state of blocks in the segment, and introduces LHWM and HHWM to manage segment space.
Low High-Water Mark (LHWM): Like the old High Water Mark.
All blocks below this block have been formatted for the table.
High High-Water Mark (HHWM)
All blocks above this block have not been formatted.
The LHWM and the HHWM may not be the same value depending on how the bitmap tree was traversed. If different the blocks between them may or may not be formatted for use. The HHWM is necessary so that direct load operation can guarantee contiguous unformatted blocks.
During parallel query, a select on v$bh shows more than 100 CR versions of TABLE_1 segment header block. It could be triggered by bitmap block(BMB) checking.
When looking v$session.event, we saw a heavy activity on:
"db file parallel read"
AWR report also shows:
db file parallel read: 202,467
Oracle says that this event happens during recovery or buffer prefetching. But in this case, it could be the multiple BMB blocks' reads from different files in which BMB blocks are located for each group.
select /*+ parallel(t,2) parallel_index(t,2) dbms_stats cursor_sharing_exact
use_weak_name_resl dynamic_sampling(0) no_monitoring no_substrb_pad
*/count(*), count("ID"), count(distinct "ID"),
sum(sys_op_opnsize("ID")), substrb(dump(min("ID"),16,0,32),1,120),
substrb(dump(max("ID"),16,0,32),1,120),
...
from "X"."TABLE_1" sample ( 5.0000000000) t;
which is generated when executing:
dbms_stats.gather_table_stats('X', 'TABLE_1', estimate_percent=>5, degree=>2);
on both Oracle 11.2.0.3.0 and 11.2.0.4.0.
The table is about 160GB and contains 20m blocks (8K per block) in ASSM LMT Managed Tablespaces, all the columns are number or varchar2.
AWR report shows the SELECT statement statistics:
Buffer Gets 14,805,983,166
Physical Reads 40,474,817
UnOptimized Read Reqs 1,881,624
TABLE_1 Segment Statistics:
Segments by Logical Reads 16,312,997,632
Segments by Physical Reads 38,580,663
Segments by Direct Physical Reads 38,557,265
Segments by Table Scans 263,660
Segments by Buffer Busy Waits 53,492
At first, one surprising big "Table Scans" indicates certainly abnormal behavior.
Huge number of "Buffer Gets" and double "Physical Reads" also explain the slow running.
"Table Scans" for Parallel Query is the Execs of "TABLE ACCESS FULL" below "PX BLOCK ITERATOR" in xplan, since "PX BLOCK ITERATOR" at first breaks up the table into granules which are then dispatched to each PX slaves. In the case of SAMPLE select, it is the Execs of "TABLE ACCESS SAMPLE BY ROWID RANGE".
The number of granules processed by each PX slave is controlled by two hidden parameters:
_px_min_granules_per_slave: minimum number of rowid range granules to generate per slave default 13
_px_max_granules_per_slave: maximum number of rowid range granules to generate per slave default 100
For instance, parallel(t,2) contributes minimum 26 (2*13) "Table Scans", and maximum 200 (2*100);
and parallel(t,16) generates minimum 208 (16*13) "Table Scans", and maximum 1600 (16*100);
Therefore when increasing degree from 2 to 16,
dbms_stats.gather_table_stats(null, 'TABLE_1', estimate_percent=>5, degree=>16);
will take 32 (8*4) hours. That is a counterintuitive behavior when using parallel query.
The "Table Scans" can be monitored by:
select * from V$segment_statistics
where object_name = 'TABLE_1' and statistic_name = 'segment scans';
The hidden parameters can be changed by, for example:
alter system set "_px_min_granules_per_slave"=19;
Searching MOS, we found:
Bug 6474009 - On ASSM tablespaces Scans using Parallel Query can be slower than in 9.2 (Doc ID 6474009.8)
which says:
Scans using Parallel Query on ASSM tablespaces on 10.2 can be slower compared to 9.2 when there is a wide separation between the High and Low High Water Mark. There can be High contention and/or a large number of accesses to bitmap blocks in PQ slaves during extent-based scans
of table/index segments.
AWR reports may show "read by other session" as one of the top wait events and Section "Buffer Wait Statistics" may report "1st level bmb" as the most important wait class.
The difference between the High and Low High Water Mark can be identified by running procedure DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM with parameter check_only=1.
The AWR report confirms the above notice:
read by other session Waits=11,302,432
1st level bmb Waits=98,112
and calling:
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM('X','TABLE_1','TABLE',NULL,1) returns 1.
MOS also gives a Workaround:
Execute procedure DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM with check_only=0 to synchronize the gap between the High and Low High Water Mark.
IMPORTANT: A patch for bug 6493013 must be installed before running that procedure.
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM only signals the existence of the gap,
but does not report the size of the gap. However, the width between low HWM and the HWM
determines the performance of full table scan (see Section "Segment Space and the High Water Mark" later in this Blog).
To find the exact gap size, we can dump segment header by:
alter system dump datafile 94 block 2246443;
Here the output:
-----------------------------------------------------------------
Extent Header:: spare1: 0 spare2: 0 #extents: 1242809 #blocks: 19884944
last map 0x9d178f31 #maps: 2446 offset: 2720
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19804642
mapblk 0x9d178f31 offset: 441
Unlocked
--------------------------------------------------------
Low HighWater Mark :
Highwater:: 0x1e243af9 ext#: 448588 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 7177417
mapblk 0x1e242fd9 offset: 225
Level 1 BMB for High HWM block: 0x9d179910
Level 1 BMB for Low HWM block: 0x1aace0d9
--------------------------------------------------------
We can see there are 19,804,642 blocks below Highwater: 0x9d179f90, but only 7,177,417 below Low HighWater Mark: 0x1e243af9. So 12,627,225 (19804642-7177417) are between (64%).
The distance between Level 1 BMB High HWM block and Low HWM block is 2,188,032,055
(0x9d179910 - 0x1aace0d9 = 2635569424 - 447537369 = 2188032055).
After synchronizing by:
DBMS_SPACE_ADMIN.ASSM_SEGMENT_SYNCHWM('X','TABLE_1','TABLE',NULL,0)
the gap is gotten closed as showed by anew header dump:
-----------------------------------------------------------------
Extent Header:: spare1: 0 spare2: 0 #extents: 1242809 #blocks: 19884944
last map 0x9d178f31 #maps: 2446 offset: 2720
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19804642
mapblk 0x9d178f31 offset: 441
Unlocked
--------------------------------------------------------
Low HighWater Mark :
Highwater:: 0x9d179f90 ext#: 1242808 blk#: 16 ext size: 16
#blocks in seg. hdr's freelists: 0
#blocks below: 19884944
mapblk 0x9d178f31 offset: 441
Level 1 BMB for High HWM block: 0x9d179910
Level 1 BMB for Low HWM block: 0x9d179910
--------------------------------------------------------
In "Low HighWater Mark" section:
-. "#blocks below: 7177417" is updated to "#blocks below: 19884944" (even bigger than 19804642).
-. "Level 1 BMB for Low HWM block: 0x1aace0d9" is changed to "Level 1 BMB for Low HWM block: 0x9d179910",
which got the same block id (0x9d179910) as "Level 1 BMB for High HWM block: 0x9d179910".
by chance, we also notice that the gap between the High and Low High Water Mark can be synchronized by:
select /*+ parallel(t, 2) */ count(*) from TABLE_1 t;
Segment Space and the High Water Mark
Oracle has a detail description about High HWM (or simply HWM) and Low HWM
(see Segment Space and the High Water Mark):
Suppose that a transaction inserts rows into the segment. The database must allocate a group of blocks to hold the rows. The allocated blocks fall below the HWM. The database formats a bitmap block in this group to hold the metadata, but does not preformat the remaining blocks in the group.
The low HWM is important in a full table scan. Because blocks below the HWM are formatted only when used, some blocks could be unformatted, as in Figure 12-25. For this reason, the database reads the bitmap block to obtain the location of the low HWM. The database reads all blocks up to the low HWM because they are known to be formatted, and then carefully reads only the formatted blocks between the low HWM and the HWM.
We can see that ASSM uses bitmap to track the state of blocks in the segment, and introduces LHWM and HHWM to manage segment space.
Low High-Water Mark (LHWM): Like the old High Water Mark.
All blocks below this block have been formatted for the table.
High High-Water Mark (HHWM)
All blocks above this block have not been formatted.
The LHWM and the HHWM may not be the same value depending on how the bitmap tree was traversed. If different the blocks between them may or may not be formatted for use. The HHWM is necessary so that direct load operation can guarantee contiguous unformatted blocks.
During parallel query, a select on v$bh shows more than 100 CR versions of TABLE_1 segment header block. It could be triggered by bitmap block(BMB) checking.
When looking v$session.event, we saw a heavy activity on:
"db file parallel read"
AWR report also shows:
db file parallel read: 202,467
Oracle says that this event happens during recovery or buffer prefetching. But in this case, it could be the multiple BMB blocks' reads from different files in which BMB blocks are located for each group.
Friday, May 23, 2014
Oracle 11g AUTO_SAMPLE_SIZE performance on Small Tables
Oracle 11g enhanced DBMS_STATS.AUTO_SAMPLE_SIZE by a new algorithm in calculating NDV
(see Blog: Improvement of AUTO sampling statistics gathering feature in Oracle Database 11g ).
Recent experience on large Databases (a few TB with mixed objects' size) reveals the performance disadvantage on small tables when using AUTO_SAMPLE_SIZE. In most case, objects under 100 MB are 20% to 40% slower.
Such behaviour can be reproduced on a small test DB. At first, create a few tables with different size. Then call dbms_stats.gather_table_stats on them, and record session statistics for each case. (see appended TestCode).
Launch the test by:
truncate table test_stats;
exec test_tab_run(10);
then collect test result by:
with sq as
(select t.*, value - lag(value) over (partition by table_name, stat_name order by ts) val
from test_stats t
where stat_name in ('CPU used by this session', 'undo change vector size', 'sorts (rows)',
'db block gets', 'db block changes', 'physical reads', 'consistent gets'))
select a.table_name, a.table_size, a.stat_name, a.val "AUTO_VAL", p.val "100%_VAL"
,(a.val - p.val) diff, round(100*(a.val - p.val)/p.val, 2) "DIFF_%"
from (select * from sq where estimate_percent = 'AUTO') a
,(select * from sq where estimate_percent = '100%') p
where a.table_name = p.table_name
and a.stat_name = p.stat_name
order by a.stat_name, a.table_size;
Above table points out:
The query on elapsed time (in millisecond) also confirms the variance of performance on object size for both methods:
with sq as
(select t.*
,(ts - lag(ts) over (partition by table_name, stat_name order by ts))dur
from test_stats t
where stat_name in ('CPU used by this session'))
select a.table_name, a.table_size
,round(extract(minute from a.dur)*60*1000 + extract(second from a.dur)*1000) "AUTO_DUR"
,round(extract(minute from p.dur)*60*1000 + extract(second from p.dur)*1000) "100%_DUR"
,round(extract(minute from (a.dur-p.dur))*60*1000 + extract(second from (a.dur-p.dur))*1000) diff_dur
from (select * from sq where estimate_percent = 'AUTO') a
,(select * from sq where estimate_percent = '100%') p
where a.table_name = p.table_name
and a.stat_name = p.stat_name
order by a.stat_name, a.table_size;
As a conclusion, this Blog demonstrated the existence of crossing point on object size. Only apart from this point, AUTO_SAMPLE_SIZE is profitable, and benefice is proportional to the object size.
By a 10046 trace when running:
exec dbms_stats.gather_table_stats(null, 'TEST_TAB_2MB', estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE);
we can see the new Operation: APPROXIMATE NDV:
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=300 pr=296 pw=0 time=246170 us)
30000 APPROXIMATE NDV AGGREGATE (cr=300 pr=296 pw=0 time=44330 us ...)
30000 TABLE ACCESS FULL TEST_TAB_2MB (cr=300 pr=296 pw=0 time=23643 us ...)
As discussed in Amit Poddar's "One Pass Distinct Sampling" (comprising details of math foundations), the most expensive operation in the old method is due to aggregate function (count (distinct ..)) to calculate the NDVs, whereas the new algorithm scans the full table once to build a synopsis per column to calculate column NDV.
To explore APPROXIMATE NDV AGGREGATE internals, Oracle designated a special event:
ORA-10832: Trace approximate NDV row source
The details of approximate NDV algorithm can be traced with event 10832 set at level 1.
The new algorithm is coded in DBMS_SQLTUNE_INTERNAL.GATHER_SQL_STATS and called by DBMS_STATS_INTERNAL.GATHER_SQL_STATS, which is again called by DBMS_STATS.GATHER_BASIC_USING_APPR_NDV, and finally by DBMS_STATS.GATHER_TABLE_STATS.
drop view stats_v;
create view stats_v as
select n.name stat_name, s.value from v$statname n, v$mystat s where n.statistic# = s.statistic#;
drop table test_stats;
create table test_stats as
select timestamp'2013-11-22 10:20:30' ts, 'TEST_TAB_xxxxxxxxxx' table_name, 0 table_size, 'AUTO_or_100%' estimate_percent, v.*
from stats_v v where 1=2;
drop table test_tab_0kb;
create table test_tab_0kb(x number, y varchar2(100));
insert into test_tab_0kb(y) values(null);
commit;
drop table test_tab_200kb;
create table test_tab_200kb(x number, y varchar2(100));
insert into test_tab_200kb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 3000;
commit;
drop table test_tab_800kb;
create table test_tab_800kb(x number, y varchar2(100));
insert into test_tab_800kb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 12000;
commit;
drop table test_tab_1mb;
create table test_tab_1mb(x number, y varchar2(100));
insert into test_tab_1mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 15000;
commit;
drop table test_tab_2mb;
create table test_tab_2mb(x number, y varchar2(100));
insert into test_tab_2mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 30000;
commit;
drop table test_tab_8mb;
create table test_tab_8mb(x number, y varchar2(100));
insert into test_tab_8mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 120000;
commit;
drop table test_tab_20mb;
create table test_tab_20mb(x number, y varchar2(100));
insert into test_tab_20mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 300000;
commit;
drop table test_tab_80mb;
create table test_tab_80mb(x number, y varchar2(100));
insert into test_tab_80mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 1200000;
commit;
create or replace procedure fill_tab(p_table_name varchar2, p_size_mb number) as
begin
for i in 1..p_size_mb loop
execute immediate 'insert into ' || p_table_name||' select * from test_tab_1mb';
end loop;
commit;
end;
/
create or replace procedure test_tab_proc (p_table_name varchar2, p_cnt number) as
l_table_size number;
procedure flush as
begin
execute immediate 'alter system flush shared_pool';
execute immediate 'alter system flush buffer_cache';
end;
begin
execute immediate 'select bytes from dba_segments where segment_name = :s' into l_table_size using p_table_name;
insert into test_stats select systimestamp, p_table_name, l_table_size, 'start', v.* from stats_v v;
flush;
for i in 1..p_cnt loop
dbms_stats.gather_table_stats(null, p_table_name, estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE);
end loop;
insert into test_stats select systimestamp, p_table_name, l_table_size, 'AUTO', v.* from stats_v v;
flush;
for i in 1..p_cnt loop
dbms_stats.gather_table_stats(null, p_table_name, estimate_percent => 100);
end loop;
insert into test_stats select systimestamp, p_table_name, l_table_size, '100%', v.* from stats_v v;
commit;
end;
/
create or replace procedure test_tab_run(p_cnt number) as
begin
test_tab_proc('TEST_TAB_0KB', p_cnt);
test_tab_proc('TEST_TAB_200KB', p_cnt);
test_tab_proc('TEST_TAB_800KB', p_cnt);
test_tab_proc('TEST_TAB_2MB', p_cnt);
test_tab_proc('TEST_TAB_8MB', p_cnt);
test_tab_proc('TEST_TAB_20MB', p_cnt);
test_tab_proc('TEST_TAB_80MB', p_cnt);
end;
/
(see Blog: Improvement of AUTO sampling statistics gathering feature in Oracle Database 11g ).
Recent experience on large Databases (a few TB with mixed objects' size) reveals the performance disadvantage on small tables when using AUTO_SAMPLE_SIZE. In most case, objects under 100 MB are 20% to 40% slower.
Such behaviour can be reproduced on a small test DB. At first, create a few tables with different size. Then call dbms_stats.gather_table_stats on them, and record session statistics for each case. (see appended TestCode).
Launch the test by:
truncate table test_stats;
exec test_tab_run(10);
then collect test result by:
with sq as
(select t.*, value - lag(value) over (partition by table_name, stat_name order by ts) val
from test_stats t
where stat_name in ('CPU used by this session', 'undo change vector size', 'sorts (rows)',
'db block gets', 'db block changes', 'physical reads', 'consistent gets'))
select a.table_name, a.table_size, a.stat_name, a.val "AUTO_VAL", p.val "100%_VAL"
,(a.val - p.val) diff, round(100*(a.val - p.val)/p.val, 2) "DIFF_%"
from (select * from sq where estimate_percent = 'AUTO') a
,(select * from sq where estimate_percent = '100%') p
where a.table_name = p.table_name
and a.stat_name = p.stat_name
order by a.stat_name, a.table_size;
| TABLE_NAME | TABLE_SIZE | STAT_NAME | AUTO_VAL | 100%_VAL | DIFF | DIFF_% |
|---|---|---|---|---|---|---|
| TEST_TAB_0KB |
131072
|
CPU used by this session |
62
|
32
|
30
|
93.75
|
| TEST_TAB_200KB |
262144
|
CPU used by this session |
48
|
35
|
13
|
37.14
|
| TEST_TAB_800KB |
917504
|
CPU used by this session |
51
|
54
|
-3
|
-5.56
|
| TEST_TAB_2MB |
2228224
|
CPU used by this session |
58
|
91
|
-33
|
-36.26
|
| TEST_TAB_8MB |
8519680
|
CPU used by this session |
89
|
289
|
-200
|
-69.2
|
| TEST_TAB_20MB |
20971520
|
CPU used by this session |
150
|
702
|
-552
|
-78.63
|
| TEST_TAB_80MB |
83755008
|
CPU used by this session |
436
|
2800
|
-2364
|
-84.43
|
| TEST_TAB_0KB |
131072
|
consistent gets |
25595
|
14167
|
11428
|
80.67
|
| TEST_TAB_200KB |
262144
|
consistent gets |
18976
|
13582
|
5394
|
39.71
|
| TEST_TAB_800KB |
917504
|
consistent gets |
19730
|
14376
|
5354
|
37.24
|
| TEST_TAB_2MB |
2228224
|
consistent gets |
21338
|
15990
|
5348
|
33.45
|
| TEST_TAB_8MB |
8519680
|
consistent gets |
28935
|
23622
|
5313
|
22.49
|
| TEST_TAB_20MB |
20971520
|
consistent gets |
44004
|
38464
|
5540
|
14.4
|
| TEST_TAB_80MB |
83755008
|
consistent gets |
124858
|
114275
|
10583
|
9.26
|
| TEST_TAB_0KB |
131072
|
db block changes |
3347
|
1748
|
1599
|
91.48
|
| TEST_TAB_200KB |
262144
|
db block changes |
2277
|
1639
|
638
|
38.93
|
| TEST_TAB_800KB |
917504
|
db block changes |
2308
|
1684
|
624
|
37.05
|
| TEST_TAB_2MB |
2228224
|
db block changes |
2344
|
1640
|
704
|
42.93
|
| TEST_TAB_8MB |
8519680
|
db block changes |
2302
|
1813
|
489
|
26.97
|
| TEST_TAB_20MB |
20971520
|
db block changes |
2318
|
1685
|
633
|
37.57
|
| TEST_TAB_80MB |
83755008
|
db block changes |
6998
|
1713
|
5285
|
308.52
|
| TEST_TAB_0KB |
131072
|
db block gets |
3531
|
1611
|
1920
|
119.18
|
| TEST_TAB_200KB |
262144
|
db block gets |
2785
|
1497
|
1288
|
86.04
|
| TEST_TAB_800KB |
917504
|
db block gets |
2786
|
1555
|
1231
|
79.16
|
| TEST_TAB_2MB |
2228224
|
db block gets |
2849
|
1499
|
1350
|
90.06
|
| TEST_TAB_8MB |
8519680
|
db block gets |
2785
|
1659
|
1126
|
67.87
|
| TEST_TAB_20MB |
20971520
|
db block gets |
2815
|
1540
|
1275
|
82.79
|
| TEST_TAB_80MB |
83755008
|
db block gets |
2765
|
1577
|
1188
|
75.33
|
| TEST_TAB_0KB |
131072
|
physical reads |
1885
|
988
|
897
|
90.79
|
| TEST_TAB_200KB |
262144
|
physical reads |
1136
|
906
|
230
|
25.39
|
| TEST_TAB_800KB |
917504
|
physical reads |
1208
|
965
|
243
|
25.18
|
| TEST_TAB_2MB |
2228224
|
physical reads |
1382
|
1146
|
236
|
20.59
|
| TEST_TAB_8MB |
8519680
|
physical reads |
2139
|
1903
|
236
|
12.4
|
| TEST_TAB_20MB |
20971520
|
physical reads |
3639
|
25991
|
-22352
|
-86
|
| TEST_TAB_80MB |
83755008
|
physical reads |
11188
|
101658
|
-90470
|
-88.99
|
| TEST_TAB_0KB |
131072
|
sorts (rows) |
13623
|
9873
|
3750
|
37.98
|
| TEST_TAB_200KB |
262144
|
sorts (rows) |
12609
|
69442
|
-56833
|
-81.84
|
| TEST_TAB_800KB |
917504
|
sorts (rows) |
12609
|
248542
|
-235933
|
-94.93
|
| TEST_TAB_2MB |
2228224
|
sorts (rows) |
12609
|
606742
|
-594133
|
-97.92
|
| TEST_TAB_8MB |
8519680
|
sorts (rows) |
12609
|
2397742
|
-2385133
|
-99.47
|
| TEST_TAB_20MB |
20971520
|
sorts (rows) |
12609
|
5979742
|
-5967133
|
-99.79
|
| TEST_TAB_80MB |
83755008
|
sorts (rows) |
12609
|
23889742
|
-23877133
|
-99.95
|
| TEST_TAB_0KB |
131072
|
undo change vector size |
143968
|
84360
|
59608
|
70.66
|
| TEST_TAB_200KB |
262144
|
undo change vector size |
92536
|
81572
|
10964
|
13.44
|
| TEST_TAB_800KB |
917504
|
undo change vector size |
102888
|
82036
|
20852
|
25.42
|
| TEST_TAB_2MB |
2228224
|
undo change vector size |
103436
|
81240
|
22196
|
27.32
|
| TEST_TAB_8MB |
8519680
|
undo change vector size |
104356
|
95100
|
9256
|
9.73
|
| TEST_TAB_20MB |
20971520
|
undo change vector size |
94504
|
90772
|
3732
|
4.11
|
| TEST_TAB_80MB |
83755008
|
undo change vector size |
94528
|
90664
|
3864
|
4.26
|
Above table points out:
- "CPU used by this session" is favorable to "AUTO_SAMPLE_SIZE" only when table size is over 800KB.
- "consistent gets", "physical reads" are increasing with table size.
These reflect the real work of gather_table_stats. - "db block changes", "db block gets", "undo change vector size" are almost constant.
but "AUTO_SAMPLE_SIZE" is mostly higher than "100%".
They stand for the base load of gather_table_stats, since gather_table_stats hardly makes any modifications on the tables.
Regardless of table size, they pertain for each call of gather_table_stats. - "sorts (rows)" is constant for "AUTO_SAMPLE_SIZE", but increasing rapidly for "100%".
This exposes the effective advantage of new algorithm.
The query on elapsed time (in millisecond) also confirms the variance of performance on object size for both methods:
with sq as
(select t.*
,(ts - lag(ts) over (partition by table_name, stat_name order by ts))dur
from test_stats t
where stat_name in ('CPU used by this session'))
select a.table_name, a.table_size
,round(extract(minute from a.dur)*60*1000 + extract(second from a.dur)*1000) "AUTO_DUR"
,round(extract(minute from p.dur)*60*1000 + extract(second from p.dur)*1000) "100%_DUR"
,round(extract(minute from (a.dur-p.dur))*60*1000 + extract(second from (a.dur-p.dur))*1000) diff_dur
from (select * from sq where estimate_percent = 'AUTO') a
,(select * from sq where estimate_percent = '100%') p
where a.table_name = p.table_name
and a.stat_name = p.stat_name
order by a.stat_name, a.table_size;
| TABLE_NAME | TABLE_SIZE | AUTO_DUR | 100%_DUR | DIFF_DUR |
|---|---|---|---|---|
| TEST_TAB_0KB |
131072
|
1852
|
882
|
970
|
| TEST_TAB_200KB |
262144
|
986
|
748
|
239
|
| TEST_TAB_800KB |
917504
|
1066
|
1029
|
37
|
| TEST_TAB_2MB |
2228224
|
1179
|
1648
|
-469
|
| TEST_TAB_8MB |
8519680
|
1645
|
4819
|
-3174
|
| TEST_TAB_20MB |
20971520
|
2650
|
11407
|
-8756
|
| TEST_TAB_80MB |
83755008
|
7300
|
44910
|
-37610
|
As a conclusion, this Blog demonstrated the existence of crossing point on object size. Only apart from this point, AUTO_SAMPLE_SIZE is profitable, and benefice is proportional to the object size.
AUTO_SAMPLE_SIZE Internals
By a 10046 trace when running:
exec dbms_stats.gather_table_stats(null, 'TEST_TAB_2MB', estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE);
we can see the new Operation: APPROXIMATE NDV:
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=300 pr=296 pw=0 time=246170 us)
30000 APPROXIMATE NDV AGGREGATE (cr=300 pr=296 pw=0 time=44330 us ...)
30000 TABLE ACCESS FULL TEST_TAB_2MB (cr=300 pr=296 pw=0 time=23643 us ...)
As discussed in Amit Poddar's "One Pass Distinct Sampling" (comprising details of math foundations), the most expensive operation in the old method is due to aggregate function (count (distinct ..)) to calculate the NDVs, whereas the new algorithm scans the full table once to build a synopsis per column to calculate column NDV.
To explore APPROXIMATE NDV AGGREGATE internals, Oracle designated a special event:
ORA-10832: Trace approximate NDV row source
The details of approximate NDV algorithm can be traced with event 10832 set at level 1.
The new algorithm is coded in DBMS_SQLTUNE_INTERNAL.GATHER_SQL_STATS and called by DBMS_STATS_INTERNAL.GATHER_SQL_STATS, which is again called by DBMS_STATS.GATHER_BASIC_USING_APPR_NDV, and finally by DBMS_STATS.GATHER_TABLE_STATS.
TestCode
drop view stats_v;
create view stats_v as
select n.name stat_name, s.value from v$statname n, v$mystat s where n.statistic# = s.statistic#;
drop table test_stats;
create table test_stats as
select timestamp'2013-11-22 10:20:30' ts, 'TEST_TAB_xxxxxxxxxx' table_name, 0 table_size, 'AUTO_or_100%' estimate_percent, v.*
from stats_v v where 1=2;
drop table test_tab_0kb;
create table test_tab_0kb(x number, y varchar2(100));
insert into test_tab_0kb(y) values(null);
commit;
drop table test_tab_200kb;
create table test_tab_200kb(x number, y varchar2(100));
insert into test_tab_200kb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 3000;
commit;
drop table test_tab_800kb;
create table test_tab_800kb(x number, y varchar2(100));
insert into test_tab_800kb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 12000;
commit;
drop table test_tab_1mb;
create table test_tab_1mb(x number, y varchar2(100));
insert into test_tab_1mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 15000;
commit;
drop table test_tab_2mb;
create table test_tab_2mb(x number, y varchar2(100));
insert into test_tab_2mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 30000;
commit;
drop table test_tab_8mb;
create table test_tab_8mb(x number, y varchar2(100));
insert into test_tab_8mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 120000;
commit;
drop table test_tab_20mb;
create table test_tab_20mb(x number, y varchar2(100));
insert into test_tab_20mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 300000;
commit;
drop table test_tab_80mb;
create table test_tab_80mb(x number, y varchar2(100));
insert into test_tab_80mb select level, rpad('abc', mod(level, 100), 'x') from dual connect by level <= 1200000;
commit;
create or replace procedure fill_tab(p_table_name varchar2, p_size_mb number) as
begin
for i in 1..p_size_mb loop
execute immediate 'insert into ' || p_table_name||' select * from test_tab_1mb';
end loop;
commit;
end;
/
create or replace procedure test_tab_proc (p_table_name varchar2, p_cnt number) as
l_table_size number;
procedure flush as
begin
execute immediate 'alter system flush shared_pool';
execute immediate 'alter system flush buffer_cache';
end;
begin
execute immediate 'select bytes from dba_segments where segment_name = :s' into l_table_size using p_table_name;
insert into test_stats select systimestamp, p_table_name, l_table_size, 'start', v.* from stats_v v;
flush;
for i in 1..p_cnt loop
dbms_stats.gather_table_stats(null, p_table_name, estimate_percent => DBMS_STATS.AUTO_SAMPLE_SIZE);
end loop;
insert into test_stats select systimestamp, p_table_name, l_table_size, 'AUTO', v.* from stats_v v;
flush;
for i in 1..p_cnt loop
dbms_stats.gather_table_stats(null, p_table_name, estimate_percent => 100);
end loop;
insert into test_stats select systimestamp, p_table_name, l_table_size, '100%', v.* from stats_v v;
commit;
end;
/
create or replace procedure test_tab_run(p_cnt number) as
begin
test_tab_proc('TEST_TAB_0KB', p_cnt);
test_tab_proc('TEST_TAB_200KB', p_cnt);
test_tab_proc('TEST_TAB_800KB', p_cnt);
test_tab_proc('TEST_TAB_2MB', p_cnt);
test_tab_proc('TEST_TAB_8MB', p_cnt);
test_tab_proc('TEST_TAB_20MB', p_cnt);
test_tab_proc('TEST_TAB_80MB', p_cnt);
end;
/
Thursday, May 8, 2014
java stored procedure calls and latch: row cache objects, and performance
In the last Blog, we demonstrated java stored procedure calls and latch: row cache objects.
Is "latch: row cache objects" a real performance problem ?
Let's run some scalability tests for both cases (See TestCode in Blog: java stored procedure calls and latch: row cache objects) on AIX Power7 System with Entitled Capacity 4, SMT=4 and Oracle 11.2.0.3.0.
begin
xpp_test.run_var(p_case => 1, p_job_var => 32, p_dur_seconds => 60);
xpp_test.run_var(p_case => 2, p_job_var => 32, p_dur_seconds => 60);
end;
/
The above code runs Case_1 and Case_2 with Jobs varying from 1 to 32 for 60 seconds.
Once the test terminated, run query:
with run as
(select case, job_cnt, sum(dur)*1000 elapsed,
sum(run_cnt) run_cnt, sum(java_cnt) java_cnt, round(sum(java_nano)/1000/1000) java_elapsed
from test_stats
group by case, job_cnt)
select r1.job_cnt, r1.elapsed,
r1.run_cnt c1_run_cnt, r2.run_cnt c2_run_cnt,
r1.java_cnt c1_java_cnt, r2.java_cnt c2_java_cnt,
r1.java_elapsed c1_java_elapsed, r2.java_elapsed c2_java_elapsed
from (select * from run where case = 1) r1
,(select * from run where case = 2) r2
where r1.job_cnt = r2.job_cnt(+)
order by r1.job_cnt;
The output shows that the throughput of both cases (C1_RUN_CNT and C2_RUN_CNT) is very closed.
Table-1
If drawing a graph with above data, we can see that throughput is linear till JOB_CNT=4, and reach its peak point at JOB_CNT=16.
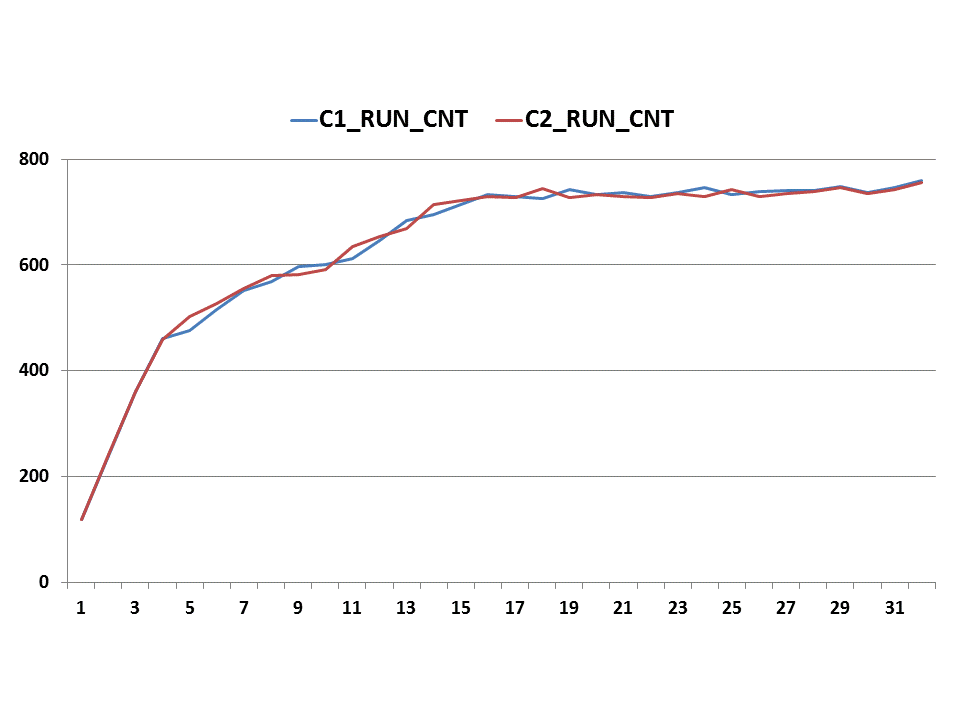 Figure-1
Figure-1
If we run the query for latch: row cache objects:
with rc as
(select s.case, s.job_cnt, (e.gets-s.gets) gets, (e.misses-s.misses) misses, (e.sleeps-s.sleeps) sleeps,
(e.spin_gets-s.spin_gets) spin_gets, (e.wait_time-s.wait_time) wait_time
from (select * from rc_latch_stats where step = 'start') s
,(select * from rc_latch_stats where step = 'end') e
where s.case = e.case and s.job_cnt = e.job_cnt)
select c1.job_cnt, c1.gets c1_gets, c2.gets c2_gets, c1.misses c1_misses, c2.misses c2_misses,
c1.sleeps c1_sleeps, c2.sleeps c2_sleeps, c1.spin_gets c1_spin_gets, c2.spin_gets c2_spin_gets,
round(c1.wait_time/1000) c1_wait_time, round(c2.wait_time/1000) c2_wait_time
from (select * from rc where case = 1) c1
,(select * from rc where case = 2) c2
where c1.job_cnt = c2.job_cnt(+)
order by c1.job_cnt;
and look its output:
Table-2
There is a broad difference of latch gets and misses between Case_1 and Case_2.
Also drawing a graph for Case_1:

Figure-2
For Case_1, latch misses reach its top at about JOB_CNT=16, and starting from JOB_CNT=15, there is a considerable latch wait_time.
One interesting query to reveal the unbalanced workload of Job sessions (UNIX processes) is:
select job_cnt, min(run_cnt) min, max(run_cnt) max, (max(run_cnt) - min(run_cnt)) delta_max
,round(avg(run_cnt), 2) avg, round(stddev(run_cnt), 2) stddev
from test_stats t
where case = 1
group by case, job_cnt
order by case, job_cnt;
which shows certain difference (STDDEV) starting from JOB_CNT = 4 on 4 Physical CPUs AIX (Entitled Capacity = 4) since at least one CPU is required to perform UNIX system and other Oracle tasks.
(Only Case_1 is showed, but Case_2 looks similar)
Table-3
Is "latch: row cache objects" a real performance problem ?
Let's run some scalability tests for both cases (See TestCode in Blog: java stored procedure calls and latch: row cache objects) on AIX Power7 System with Entitled Capacity 4, SMT=4 and Oracle 11.2.0.3.0.
begin
xpp_test.run_var(p_case => 1, p_job_var => 32, p_dur_seconds => 60);
xpp_test.run_var(p_case => 2, p_job_var => 32, p_dur_seconds => 60);
end;
/
The above code runs Case_1 and Case_2 with Jobs varying from 1 to 32 for 60 seconds.
Scalability
Once the test terminated, run query:
with run as
(select case, job_cnt, sum(dur)*1000 elapsed,
sum(run_cnt) run_cnt, sum(java_cnt) java_cnt, round(sum(java_nano)/1000/1000) java_elapsed
from test_stats
group by case, job_cnt)
select r1.job_cnt, r1.elapsed,
r1.run_cnt c1_run_cnt, r2.run_cnt c2_run_cnt,
r1.java_cnt c1_java_cnt, r2.java_cnt c2_java_cnt,
r1.java_elapsed c1_java_elapsed, r2.java_elapsed c2_java_elapsed
from (select * from run where case = 1) r1
,(select * from run where case = 2) r2
where r1.job_cnt = r2.job_cnt(+)
order by r1.job_cnt;
The output shows that the throughput of both cases (C1_RUN_CNT and C2_RUN_CNT) is very closed.
| JOB_CNT | ELAPSED | C1_RUN_CNT | C2_RUN_CNT | C1_JAVA_CNT | C2_JAVA_CNT | C1_JAVA_ELAPSED | C2_JAVA_ELAPSED |
|---|---|---|---|---|---|---|---|
1
|
60000
|
118
|
119
|
86612
|
119
|
390
|
1599
|
2
|
120000
|
240
|
242
|
176160
|
242
|
794
|
2944
|
3
|
180000
|
360
|
361
|
264240
|
361
|
1196
|
4439
|
4
|
240000
|
461
|
459
|
338374
|
459
|
1566
|
5756
|
5
|
300000
|
476
|
503
|
349384
|
503
|
1852
|
7055
|
6
|
360000
|
515
|
527
|
378010
|
527
|
2101
|
8040
|
7
|
420000
|
551
|
555
|
404434
|
555
|
2408
|
8952
|
8
|
480000
|
569
|
580
|
417646
|
580
|
2689
|
10464
|
9
|
540000
|
597
|
582
|
438198
|
582
|
2978
|
11459
|
10
|
600000
|
601
|
591
|
441134
|
591
|
3163
|
12797
|
11
|
660000
|
613
|
635
|
449942
|
635
|
3350
|
14150
|
12
|
720000
|
646
|
654
|
474164
|
654
|
3655
|
15019
|
13
|
780000
|
683
|
668
|
501322
|
668
|
3912
|
16619
|
14
|
840000
|
696
|
714
|
510864
|
714
|
4260
|
16985
|
15
|
900000
|
714
|
722
|
524076
|
722
|
4435
|
19440
|
16
|
960000
|
733
|
730
|
538022
|
730
|
4822
|
20250
|
17
|
1020000
|
730
|
728
|
535820
|
728
|
4947
|
22637
|
18
|
1080000
|
726
|
744
|
532884
|
744
|
5022
|
21034
|
19
|
1140000
|
743
|
727
|
545362
|
727
|
5274
|
23924
|
20
|
1200000
|
734
|
733
|
538756
|
733
|
5611
|
24402
|
21
|
1260000
|
737
|
729
|
540958
|
729
|
6075
|
26138
|
22
|
1320000
|
730
|
727
|
535820
|
727
|
6406
|
28011
|
23
|
1380000
|
737
|
735
|
540958
|
735
|
6555
|
27972
|
24
|
1440000
|
746
|
730
|
547564
|
730
|
7040
|
30529
|
25
|
1500000
|
733
|
742
|
538022
|
742
|
7181
|
29288
|
26
|
1560000
|
738
|
729
|
541692
|
729
|
6620
|
33637
|
27
|
1620000
|
740
|
735
|
543160
|
735
|
7269
|
32531
|
28
|
1680000
|
741
|
738
|
543894
|
738
|
7881
|
36467
|
29
|
1740000
|
749
|
747
|
549766
|
747
|
7652
|
34837
|
30
|
1800000
|
737
|
735
|
540958
|
735
|
8285
|
37758
|
31
|
1860000
|
746
|
743
|
547564
|
743
|
8759
|
38612
|
32
|
1920000
|
759
|
755
|
557106
|
755
|
8326
|
40002
|
Table-1
If drawing a graph with above data, we can see that throughput is linear till JOB_CNT=4, and reach its peak point at JOB_CNT=16.
Latch: row cache objects
If we run the query for latch: row cache objects:
with rc as
(select s.case, s.job_cnt, (e.gets-s.gets) gets, (e.misses-s.misses) misses, (e.sleeps-s.sleeps) sleeps,
(e.spin_gets-s.spin_gets) spin_gets, (e.wait_time-s.wait_time) wait_time
from (select * from rc_latch_stats where step = 'start') s
,(select * from rc_latch_stats where step = 'end') e
where s.case = e.case and s.job_cnt = e.job_cnt)
select c1.job_cnt, c1.gets c1_gets, c2.gets c2_gets, c1.misses c1_misses, c2.misses c2_misses,
c1.sleeps c1_sleeps, c2.sleeps c2_sleeps, c1.spin_gets c1_spin_gets, c2.spin_gets c2_spin_gets,
round(c1.wait_time/1000) c1_wait_time, round(c2.wait_time/1000) c2_wait_time
from (select * from rc where case = 1) c1
,(select * from rc where case = 2) c2
where c1.job_cnt = c2.job_cnt(+)
order by c1.job_cnt;
and look its output:
| JOB_CNT | C1_GETS | C2_GETS | C1_MISSES | C2_MISSES | C1_SLEEPS | C2_SLEEPS | C1_SPIN_GETS | C2_SPIN_GETS | C1_WAIT_TIME | C2_WAIT_TIME |
|---|---|---|---|---|---|---|---|---|---|---|
1
|
261925
|
38360
|
1
|
47
|
0
|
0
|
1
|
47
|
0
|
0
|
2
|
590567
|
4070
|
1950
|
0
|
0
|
0
|
1950
|
0
|
0
|
0
|
3
|
755390
|
2755
|
6342
|
0
|
0
|
0
|
6342
|
0
|
0
|
0
|
4
|
941682
|
3459
|
13772
|
0
|
2
|
0
|
13770
|
0
|
3
|
0
|
5
|
958751
|
4947
|
60853
|
0
|
4
|
0
|
60850
|
0
|
14
|
0
|
6
|
1128800
|
5224
|
92700
|
146
|
1
|
0
|
92699
|
146
|
1
|
0
|
7
|
1193847
|
4719
|
102209
|
31
|
1
|
0
|
102208
|
31
|
1
|
0
|
8
|
1219302
|
19716
|
151143
|
0
|
0
|
0
|
151143
|
0
|
0
|
0
|
9
|
1261478
|
5227
|
155337
|
8
|
13
|
0
|
155324
|
8
|
464
|
0
|
10
|
1256130
|
5404
|
195400
|
0
|
1
|
0
|
195399
|
0
|
0
|
0
|
11
|
1264005
|
7931
|
251793
|
27
|
0
|
0
|
251793
|
27
|
0
|
0
|
12
|
1320357
|
6014
|
254131
|
73
|
1
|
0
|
254130
|
73
|
0
|
0
|
13
|
1492126
|
7266
|
394229
|
121
|
0
|
0
|
394229
|
121
|
0
|
0
|
14
|
1496853
|
6948
|
408408
|
173
|
0
|
0
|
408408
|
173
|
0
|
0
|
15
|
1511372
|
7124
|
417898
|
472
|
13
|
0
|
417885
|
472
|
1795
|
0
|
16
|
1521562
|
8392
|
437642
|
283
|
11
|
0
|
437631
|
283
|
2271
|
0
|
17
|
1494286
|
20916
|
355035
|
179
|
36
|
0
|
354999
|
179
|
4324
|
0
|
18
|
1459280
|
7891
|
320098
|
420
|
53
|
0
|
320046
|
420
|
9841
|
0
|
19
|
1611370
|
9055
|
335870
|
212
|
37
|
0
|
335833
|
212
|
9564
|
0
|
20
|
1566755
|
9186
|
280001
|
218
|
100
|
5
|
279903
|
213
|
23946
|
530
|
21
|
1553970
|
8186
|
268234
|
52
|
70
|
14
|
268165
|
38
|
21438
|
3470
|
22
|
1499580
|
9350
|
230573
|
112
|
157
|
0
|
230420
|
112
|
40523
|
0
|
23
|
1474488
|
8538
|
244989
|
142
|
158
|
4
|
244832
|
138
|
36357
|
392
|
24
|
1628831
|
9677
|
229768
|
69
|
197
|
0
|
229573
|
69
|
54006
|
0
|
25
|
1568732
|
11112
|
226365
|
344
|
392
|
5
|
225984
|
339
|
103739
|
311
|
26
|
1548840
|
22742
|
229974
|
155
|
323
|
0
|
229656
|
155
|
76637
|
0
|
27
|
1519217
|
10326
|
204424
|
148
|
418
|
0
|
204014
|
148
|
86043
|
0
|
28
|
1479227
|
9322
|
200061
|
78
|
476
|
0
|
199596
|
78
|
102191
|
0
|
29
|
1641837
|
9841
|
226975
|
220
|
493
|
0
|
226486
|
220
|
107470
|
0
|
30
|
1556361
|
12102
|
210739
|
159
|
449
|
1
|
210305
|
158
|
93532
|
18
|
31
|
1518952
|
10004
|
191122
|
255
|
558
|
22
|
190572
|
233
|
104639
|
4785
|
32
|
1544149
|
10248
|
191564
|
254
|
628
|
9
|
190940
|
245
|
114982
|
447
|
Table-2
There is a broad difference of latch gets and misses between Case_1 and Case_2.
Also drawing a graph for Case_1:
Figure-2
For Case_1, latch misses reach its top at about JOB_CNT=16, and starting from JOB_CNT=15, there is a considerable latch wait_time.
Unbalanced Workload
One interesting query to reveal the unbalanced workload of Job sessions (UNIX processes) is:
select job_cnt, min(run_cnt) min, max(run_cnt) max, (max(run_cnt) - min(run_cnt)) delta_max
,round(avg(run_cnt), 2) avg, round(stddev(run_cnt), 2) stddev
from test_stats t
where case = 1
group by case, job_cnt
order by case, job_cnt;
which shows certain difference (STDDEV) starting from JOB_CNT = 4 on 4 Physical CPUs AIX (Entitled Capacity = 4) since at least one CPU is required to perform UNIX system and other Oracle tasks.
(Only Case_1 is showed, but Case_2 looks similar)
| JOB_CNT | MIN | MAX | DELTA_MAX | AVG | STDDEV |
|---|---|---|---|---|---|
1
|
118
|
118
|
0
|
118
|
0
|
2
|
120
|
120
|
0
|
120
|
0
|
3
|
120
|
120
|
0
|
120
|
0
|
4
|
109
|
120
|
11
|
115.25
|
5.62
|
5
|
74
|
119
|
45
|
95.2
|
19.98
|
6
|
75
|
97
|
22
|
85.83
|
7.7
|
7
|
66
|
100
|
34
|
78.71
|
13.05
|
8
|
63
|
77
|
14
|
71.13
|
4.82
|
9
|
58
|
76
|
18
|
66.33
|
6.3
|
10
|
56
|
73
|
17
|
60.1
|
4.95
|
11
|
48
|
67
|
19
|
55.73
|
6.26
|
12
|
49
|
64
|
15
|
53.83
|
5.06
|
13
|
47
|
66
|
19
|
52.54
|
6.1
|
14
|
46
|
65
|
19
|
49.71
|
5.95
|
15
|
45
|
51
|
6
|
47.6
|
2.2
|
16
|
44
|
47
|
3
|
45.81
|
0.75
|
17
|
38
|
46
|
8
|
42.94
|
2.05
|
18
|
35
|
44
|
9
|
40.33
|
2.47
|
19
|
32
|
46
|
14
|
39.11
|
4.23
|
20
|
32
|
43
|
11
|
36.7
|
3.7
|
21
|
28
|
42
|
14
|
35.1
|
4.37
|
22
|
25
|
39
|
14
|
33.18
|
3.43
|
23
|
26
|
39
|
13
|
32.04
|
3.13
|
24
|
25
|
36
|
11
|
31.08
|
2.65
|
25
|
25
|
32
|
7
|
29.32
|
1.73
|
26
|
25
|
35
|
10
|
28.38
|
2.5
|
27
|
25
|
33
|
8
|
27.41
|
1.89
|
28
|
24
|
30
|
6
|
26.46
|
1.53
|
29
|
24
|
28
|
4
|
25.83
|
1.07
|
30
|
22
|
28
|
6
|
24.57
|
1.33
|
31
|
22
|
33
|
11
|
24.06
|
2.06
|
32
|
21
|
30
|
9
|
23.72
|
1.9
|
Table-3
Subscribe to:
Comments (Atom)