Is "latch: row cache objects" a real performance problem ?
Let's run some scalability tests for both cases (See TestCode in Blog: java stored procedure calls and latch: row cache objects) on AIX Power7 System with Entitled Capacity 4, SMT=4 and Oracle 11.2.0.3.0.
begin
xpp_test.run_var(p_case => 1, p_job_var => 32, p_dur_seconds => 60);
xpp_test.run_var(p_case => 2, p_job_var => 32, p_dur_seconds => 60);
end;
/
The above code runs Case_1 and Case_2 with Jobs varying from 1 to 32 for 60 seconds.
Scalability
Once the test terminated, run query:
with run as
(select case, job_cnt, sum(dur)*1000 elapsed,
sum(run_cnt) run_cnt, sum(java_cnt) java_cnt, round(sum(java_nano)/1000/1000) java_elapsed
from test_stats
group by case, job_cnt)
select r1.job_cnt, r1.elapsed,
r1.run_cnt c1_run_cnt, r2.run_cnt c2_run_cnt,
r1.java_cnt c1_java_cnt, r2.java_cnt c2_java_cnt,
r1.java_elapsed c1_java_elapsed, r2.java_elapsed c2_java_elapsed
from (select * from run where case = 1) r1
,(select * from run where case = 2) r2
where r1.job_cnt = r2.job_cnt(+)
order by r1.job_cnt;
The output shows that the throughput of both cases (C1_RUN_CNT and C2_RUN_CNT) is very closed.
| JOB_CNT | ELAPSED | C1_RUN_CNT | C2_RUN_CNT | C1_JAVA_CNT | C2_JAVA_CNT | C1_JAVA_ELAPSED | C2_JAVA_ELAPSED |
|---|---|---|---|---|---|---|---|
1
|
60000
|
118
|
119
|
86612
|
119
|
390
|
1599
|
2
|
120000
|
240
|
242
|
176160
|
242
|
794
|
2944
|
3
|
180000
|
360
|
361
|
264240
|
361
|
1196
|
4439
|
4
|
240000
|
461
|
459
|
338374
|
459
|
1566
|
5756
|
5
|
300000
|
476
|
503
|
349384
|
503
|
1852
|
7055
|
6
|
360000
|
515
|
527
|
378010
|
527
|
2101
|
8040
|
7
|
420000
|
551
|
555
|
404434
|
555
|
2408
|
8952
|
8
|
480000
|
569
|
580
|
417646
|
580
|
2689
|
10464
|
9
|
540000
|
597
|
582
|
438198
|
582
|
2978
|
11459
|
10
|
600000
|
601
|
591
|
441134
|
591
|
3163
|
12797
|
11
|
660000
|
613
|
635
|
449942
|
635
|
3350
|
14150
|
12
|
720000
|
646
|
654
|
474164
|
654
|
3655
|
15019
|
13
|
780000
|
683
|
668
|
501322
|
668
|
3912
|
16619
|
14
|
840000
|
696
|
714
|
510864
|
714
|
4260
|
16985
|
15
|
900000
|
714
|
722
|
524076
|
722
|
4435
|
19440
|
16
|
960000
|
733
|
730
|
538022
|
730
|
4822
|
20250
|
17
|
1020000
|
730
|
728
|
535820
|
728
|
4947
|
22637
|
18
|
1080000
|
726
|
744
|
532884
|
744
|
5022
|
21034
|
19
|
1140000
|
743
|
727
|
545362
|
727
|
5274
|
23924
|
20
|
1200000
|
734
|
733
|
538756
|
733
|
5611
|
24402
|
21
|
1260000
|
737
|
729
|
540958
|
729
|
6075
|
26138
|
22
|
1320000
|
730
|
727
|
535820
|
727
|
6406
|
28011
|
23
|
1380000
|
737
|
735
|
540958
|
735
|
6555
|
27972
|
24
|
1440000
|
746
|
730
|
547564
|
730
|
7040
|
30529
|
25
|
1500000
|
733
|
742
|
538022
|
742
|
7181
|
29288
|
26
|
1560000
|
738
|
729
|
541692
|
729
|
6620
|
33637
|
27
|
1620000
|
740
|
735
|
543160
|
735
|
7269
|
32531
|
28
|
1680000
|
741
|
738
|
543894
|
738
|
7881
|
36467
|
29
|
1740000
|
749
|
747
|
549766
|
747
|
7652
|
34837
|
30
|
1800000
|
737
|
735
|
540958
|
735
|
8285
|
37758
|
31
|
1860000
|
746
|
743
|
547564
|
743
|
8759
|
38612
|
32
|
1920000
|
759
|
755
|
557106
|
755
|
8326
|
40002
|
Table-1
If drawing a graph with above data, we can see that throughput is linear till JOB_CNT=4, and reach its peak point at JOB_CNT=16.
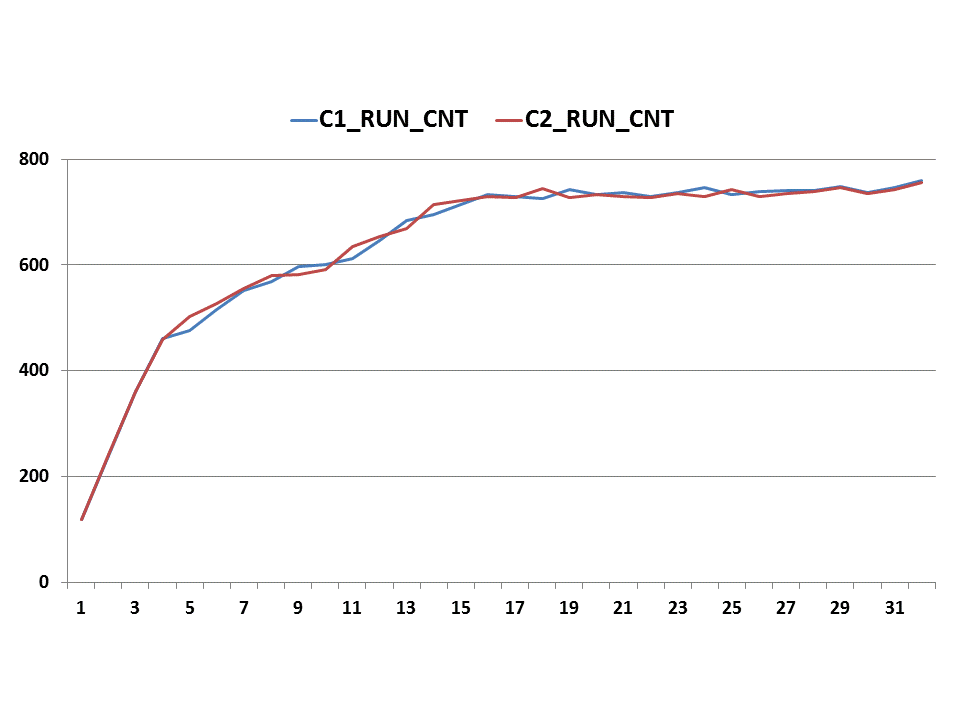
Latch: row cache objects
If we run the query for latch: row cache objects:
with rc as
(select s.case, s.job_cnt, (e.gets-s.gets) gets, (e.misses-s.misses) misses, (e.sleeps-s.sleeps) sleeps,
(e.spin_gets-s.spin_gets) spin_gets, (e.wait_time-s.wait_time) wait_time
from (select * from rc_latch_stats where step = 'start') s
,(select * from rc_latch_stats where step = 'end') e
where s.case = e.case and s.job_cnt = e.job_cnt)
select c1.job_cnt, c1.gets c1_gets, c2.gets c2_gets, c1.misses c1_misses, c2.misses c2_misses,
c1.sleeps c1_sleeps, c2.sleeps c2_sleeps, c1.spin_gets c1_spin_gets, c2.spin_gets c2_spin_gets,
round(c1.wait_time/1000) c1_wait_time, round(c2.wait_time/1000) c2_wait_time
from (select * from rc where case = 1) c1
,(select * from rc where case = 2) c2
where c1.job_cnt = c2.job_cnt(+)
order by c1.job_cnt;
and look its output:
| JOB_CNT | C1_GETS | C2_GETS | C1_MISSES | C2_MISSES | C1_SLEEPS | C2_SLEEPS | C1_SPIN_GETS | C2_SPIN_GETS | C1_WAIT_TIME | C2_WAIT_TIME |
|---|---|---|---|---|---|---|---|---|---|---|
1
|
261925
|
38360
|
1
|
47
|
0
|
0
|
1
|
47
|
0
|
0
|
2
|
590567
|
4070
|
1950
|
0
|
0
|
0
|
1950
|
0
|
0
|
0
|
3
|
755390
|
2755
|
6342
|
0
|
0
|
0
|
6342
|
0
|
0
|
0
|
4
|
941682
|
3459
|
13772
|
0
|
2
|
0
|
13770
|
0
|
3
|
0
|
5
|
958751
|
4947
|
60853
|
0
|
4
|
0
|
60850
|
0
|
14
|
0
|
6
|
1128800
|
5224
|
92700
|
146
|
1
|
0
|
92699
|
146
|
1
|
0
|
7
|
1193847
|
4719
|
102209
|
31
|
1
|
0
|
102208
|
31
|
1
|
0
|
8
|
1219302
|
19716
|
151143
|
0
|
0
|
0
|
151143
|
0
|
0
|
0
|
9
|
1261478
|
5227
|
155337
|
8
|
13
|
0
|
155324
|
8
|
464
|
0
|
10
|
1256130
|
5404
|
195400
|
0
|
1
|
0
|
195399
|
0
|
0
|
0
|
11
|
1264005
|
7931
|
251793
|
27
|
0
|
0
|
251793
|
27
|
0
|
0
|
12
|
1320357
|
6014
|
254131
|
73
|
1
|
0
|
254130
|
73
|
0
|
0
|
13
|
1492126
|
7266
|
394229
|
121
|
0
|
0
|
394229
|
121
|
0
|
0
|
14
|
1496853
|
6948
|
408408
|
173
|
0
|
0
|
408408
|
173
|
0
|
0
|
15
|
1511372
|
7124
|
417898
|
472
|
13
|
0
|
417885
|
472
|
1795
|
0
|
16
|
1521562
|
8392
|
437642
|
283
|
11
|
0
|
437631
|
283
|
2271
|
0
|
17
|
1494286
|
20916
|
355035
|
179
|
36
|
0
|
354999
|
179
|
4324
|
0
|
18
|
1459280
|
7891
|
320098
|
420
|
53
|
0
|
320046
|
420
|
9841
|
0
|
19
|
1611370
|
9055
|
335870
|
212
|
37
|
0
|
335833
|
212
|
9564
|
0
|
20
|
1566755
|
9186
|
280001
|
218
|
100
|
5
|
279903
|
213
|
23946
|
530
|
21
|
1553970
|
8186
|
268234
|
52
|
70
|
14
|
268165
|
38
|
21438
|
3470
|
22
|
1499580
|
9350
|
230573
|
112
|
157
|
0
|
230420
|
112
|
40523
|
0
|
23
|
1474488
|
8538
|
244989
|
142
|
158
|
4
|
244832
|
138
|
36357
|
392
|
24
|
1628831
|
9677
|
229768
|
69
|
197
|
0
|
229573
|
69
|
54006
|
0
|
25
|
1568732
|
11112
|
226365
|
344
|
392
|
5
|
225984
|
339
|
103739
|
311
|
26
|
1548840
|
22742
|
229974
|
155
|
323
|
0
|
229656
|
155
|
76637
|
0
|
27
|
1519217
|
10326
|
204424
|
148
|
418
|
0
|
204014
|
148
|
86043
|
0
|
28
|
1479227
|
9322
|
200061
|
78
|
476
|
0
|
199596
|
78
|
102191
|
0
|
29
|
1641837
|
9841
|
226975
|
220
|
493
|
0
|
226486
|
220
|
107470
|
0
|
30
|
1556361
|
12102
|
210739
|
159
|
449
|
1
|
210305
|
158
|
93532
|
18
|
31
|
1518952
|
10004
|
191122
|
255
|
558
|
22
|
190572
|
233
|
104639
|
4785
|
32
|
1544149
|
10248
|
191564
|
254
|
628
|
9
|
190940
|
245
|
114982
|
447
|
Table-2
There is a broad difference of latch gets and misses between Case_1 and Case_2.
Also drawing a graph for Case_1:

Figure-2
For Case_1, latch misses reach its top at about JOB_CNT=16, and starting from JOB_CNT=15, there is a considerable latch wait_time.
Unbalanced Workload
One interesting query to reveal the unbalanced workload of Job sessions (UNIX processes) is:
select job_cnt, min(run_cnt) min, max(run_cnt) max, (max(run_cnt) - min(run_cnt)) delta_max
,round(avg(run_cnt), 2) avg, round(stddev(run_cnt), 2) stddev
from test_stats t
where case = 1
group by case, job_cnt
order by case, job_cnt;
which shows certain difference (STDDEV) starting from JOB_CNT = 4 on 4 Physical CPUs AIX (Entitled Capacity = 4) since at least one CPU is required to perform UNIX system and other Oracle tasks.
(Only Case_1 is showed, but Case_2 looks similar)
| JOB_CNT | MIN | MAX | DELTA_MAX | AVG | STDDEV |
|---|---|---|---|---|---|
1
|
118
|
118
|
0
|
118
|
0
|
2
|
120
|
120
|
0
|
120
|
0
|
3
|
120
|
120
|
0
|
120
|
0
|
4
|
109
|
120
|
11
|
115.25
|
5.62
|
5
|
74
|
119
|
45
|
95.2
|
19.98
|
6
|
75
|
97
|
22
|
85.83
|
7.7
|
7
|
66
|
100
|
34
|
78.71
|
13.05
|
8
|
63
|
77
|
14
|
71.13
|
4.82
|
9
|
58
|
76
|
18
|
66.33
|
6.3
|
10
|
56
|
73
|
17
|
60.1
|
4.95
|
11
|
48
|
67
|
19
|
55.73
|
6.26
|
12
|
49
|
64
|
15
|
53.83
|
5.06
|
13
|
47
|
66
|
19
|
52.54
|
6.1
|
14
|
46
|
65
|
19
|
49.71
|
5.95
|
15
|
45
|
51
|
6
|
47.6
|
2.2
|
16
|
44
|
47
|
3
|
45.81
|
0.75
|
17
|
38
|
46
|
8
|
42.94
|
2.05
|
18
|
35
|
44
|
9
|
40.33
|
2.47
|
19
|
32
|
46
|
14
|
39.11
|
4.23
|
20
|
32
|
43
|
11
|
36.7
|
3.7
|
21
|
28
|
42
|
14
|
35.1
|
4.37
|
22
|
25
|
39
|
14
|
33.18
|
3.43
|
23
|
26
|
39
|
13
|
32.04
|
3.13
|
24
|
25
|
36
|
11
|
31.08
|
2.65
|
25
|
25
|
32
|
7
|
29.32
|
1.73
|
26
|
25
|
35
|
10
|
28.38
|
2.5
|
27
|
25
|
33
|
8
|
27.41
|
1.89
|
28
|
24
|
30
|
6
|
26.46
|
1.53
|
29
|
24
|
28
|
4
|
25.83
|
1.07
|
30
|
22
|
28
|
6
|
24.57
|
1.33
|
31
|
22
|
33
|
11
|
24.06
|
2.06
|
32
|
21
|
30
|
9
|
23.72
|
1.9
|
Table-3